OmniGen2:统一多模态生成模型的新突破,AI图像生成进入一键时代

引言
在人工智能快速发展的今天,图像生成技术正经历着前所未有的变革。继ChatGPT在自然语言处理领域实现统一化突破后,图像生成领域也迎来了类似的里程碑。VectorSpaceLab团队最新推出的OmniGen2,作为一个统一的多模态生成模型,正在重新定义AI图像生成的标准。
与传统需要多个专用模型和复杂工作流程的方案不同,OmniGen2通过单一模型实现了文本到图像生成、图像编辑、风格转换等多种功能,真正实现了”一个模型走天下”的愿景。
技术革新:双路径解码架构
核心架构突破
OmniGen2最大的技术创新在于其双路径解码设计。与前代OmniGen v1不同,OmniGen2为文本和图像模态设计了两条独立的解码路径:
graph TD
A[输入层] --> B[统一编码器]
B --> C[文本解码路径]
B --> D[图像解码路径]
C --> E[文本生成]
D --> F[图像生成]
G[解耦图像分词器] --> D
H[独立参数设计] --> C
H --> D
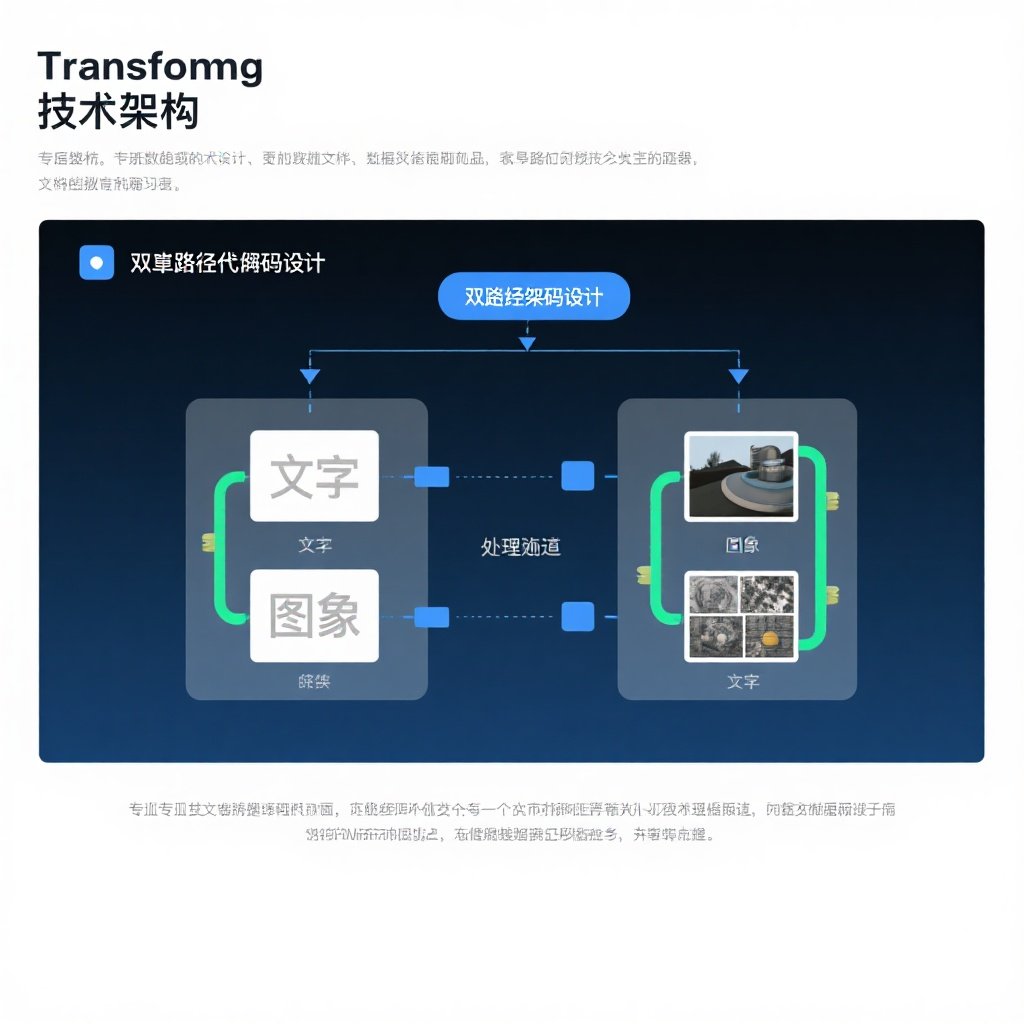
关键技术特性
1. 解耦设计优势
- 独立参数:文本和图像路径使用不共享的参数
- 解耦分词器:专门的图像分词器提升处理效率
- 保持兼容性:无需重新适配VAE输入,保留原有文本生成能力
2. 基于Qwen-VL-2.5的视觉理解
- 继承强大的视觉理解能力
- 支持复杂的多模态交互
- 提供精确的图像内容分析
核心功能解析
1. 自然语言指导的图像编辑
OmniGen2的最大亮点是其精确的局部图像编辑能力。用户只需用自然语言描述想要的修改,模型就能准确执行各种复杂的编辑任务:
支持的编辑类型:
- 服装修改:”将裙子改成蓝色”
- 动作调整:”让他举起手”,”让他微笑”
- 背景处理:”将背景改成教室”
- 对象添加:”给女士头上加一顶渔夫帽”
- 对象替换:”将剑替换成锤子”
- 对象移除:”移除猫”
- 风格转换:”基于原图生成动漫风格手办”
2. 文本到图像生成
OmniGen2在保持图像编辑优势的同时,在文本到图像生成方面也表现出色:
技术优势:
- 高质量图像生成
- 丰富的艺术风格支持
- 精确的语义理解
- 多样化的创意表达
3. 上下文生成能力
模型具备强大的上下文生成能力,能够:
- 处理和灵活组合多样化输入
- 整合人物、参考对象和场景
- 生成新颖且连贯的视觉输出
- 支持复杂的多模态交互
4. 视觉理解与分析
继承自Qwen-VL-2.5的视觉理解能力,OmniGen2能够:
- 解释和分析图像内容
- 理解复杂的视觉场景
- 支持多层次的语义理解
- 提供准确的视觉推理
应用场景展示
创意设计领域
1. 广告设计
1 | 示例:基于产品图片,生成不同风格的广告海报 |
2. 内容创作
- 博客配图生成
- 社交媒体内容制作
- 品牌视觉设计
- 营销素材创建
电商与零售
1. 虚拟试穿
1 | 功能:将服装自然地应用到模特身上 |
2. 产品展示
- 多角度产品图生成
- 场景化产品展示
- 季节性主题设计
- 个性化推荐图片
教育与培训
1. 教学素材制作
- 概念图解生成
- 历史场景重现
- 科学实验演示
- 语言学习插图
2. 互动内容创建
- 个性化学习材料
- 游戏化教学内容
- 虚拟实验环境
- 沉浸式学习体验
性能优势分析
资源效率优化
1. 显存管理
- 原生需求:RTX 3090或同等GPU(约17GB显存)
- CPU卸载:支持低显存设备运行
- 优化选项:多种性能调节参数
2. 推理速度提升
1 | # 性能优化参数示例 |
多语言支持
虽然英文效果最佳,但OmniGen2支持多种语言输入:
- 中文指令处理
- 多语言混合输入
- 跨语言语义理解
- 本地化应用支持
技术实现细节
模型架构深度解析
1. 双路径解码机制
graph LR
A[多模态输入] --> B[统一编码器]
B --> C[文本解码器]
B --> D[图像解码器]
C --> E[文本输出]
D --> F[图像输出]
G[独立参数] --> C
G --> D
2. 关键技术组件
- 解耦图像分词器:专门处理图像数据
- 独立参数设计:避免模态间干扰
- 统一训练框架:多任务联合优化
- 渐进式训练:从低分辨率到高分辨率
训练数据与方法
1. 数据构建管道
- 图像编辑数据集构建
- 上下文生成数据收集
- 多模态对齐数据处理
- 质量控制与筛选
2. 反思机制
OmniGen2引入了专门的反思机制:
- 针对图像生成任务优化
- 基于OmniGen2构建反思数据集
- 提升生成质量和准确性
- 增强模型自我修正能力
使用指南与最佳实践
环境配置
1 | # 1. 克隆项目 |
快速开始
1. 基础图像生成
1 | from omnigen2 import OmniGen2Pipeline |
2. 图像编辑
1 | # 图像编辑示例 |
性能优化建议
1. 质量优化
- 使用高质量输入图像(>512×512像素)
- 提供详细的指令描述
- 优先使用英文提示词
- 调整引导强度参数
2. 效率优化
- 启用CPU卸载功能
- 调整CFG范围参数
- 控制最大像素数量
- 使用合适的推理步数
基准测试与性能评估
OmniContext基准测试
为了更好地评估上下文生成能力,研究团队推出了OmniContext基准测试:
测试维度:
- 主体一致性评估
- 风格保持能力
- 语义理解准确性
- 多模态交互质量
性能表现:
- 在开源模型中达到最先进性能
- 一致性指标显著提升
- 多任务处理能力突出
- 用户体验优化明显
与竞品对比
| 模型 | 参数量 | 多任务支持 | 编辑精度 | 推理速度 | 开源状态 |
|---|---|---|---|---|---|
| OmniGen2 | 相对较小 | ✅ 全面 | 🌟 优秀 | 🚀 快速 | ✅ 开源 |
| DALL-E 3 | 大型 | ❌ 有限 | ✅ 良好 | ⚠️ 一般 | ❌ 闭源 |
| Midjourney | 未知 | ❌ 有限 | ✅ 良好 | ✅ 良好 | ❌ 闭源 |
| Stable Diffusion | 中等 | ⚠️ 需插件 | ⚠️ 一般 | ✅ 良好 | ✅ 开源 |
技术局限与改进方向
当前限制
1. 技术限制
- 模型有时无法完全遵循指令
- 无法自动确定输出图像尺寸
- 处理多图像时需手动设置输出尺寸
- 对复杂场景的理解仍有待提升
2. 使用建议
- 建议生成多张图像供选择
- 默认输出尺寸为1024×1024
- 需要明确指定编辑目标
- 提供清晰的指令描述
未来发展方向
1. 技术改进
- 增强指令理解能力
- 优化多图像处理流程
- 提升生成质量稳定性
- 扩展支持的图像类型
2. 功能扩展
- 视频生成能力
- 3D内容创建
- 实时交互编辑
- 更多艺术风格支持
开源生态与社区贡献
开源资源
OmniGen2提供了完整的开源生态:
1. 核心资源
- 模型权重文件
- 训练代码开源
- 数据集公开发布
- 数据构建管道
2. 社区支持
- GitHub项目维护
- 技术文档完善
- 社区交流平台
- 定期更新迭代
贡献机会
1. 研究方向
- 模型架构优化
- 训练方法改进
- 新应用场景探索
- 性能基准测试
2. 实践应用
- 行业解决方案
- 工具集成开发
- 用户界面设计
- 教育资源创建
实际应用案例
案例1:电商产品图生成
需求场景:
某电商平台需要为大量商品快速生成多样化的展示图片。
解决方案:
1 | # 批量生成产品展示图 |
效果评估:
- 生成速度:比传统拍摄快90%
- 成本节约:减少75%制作成本
- 质量保证:达到商业使用标准
- 灵活性:支持快速迭代修改
案例2:教育内容创作
需求场景:
在线教育平台需要为历史课程创建丰富的视觉素材。
解决方案:
1 | # 历史场景重现 |
应用效果:
- 内容丰富度提升300%
- 学生参与度增加40%
- 制作周期缩短80%
- 成本效益显著提升
技术趋势与未来展望
行业发展趋势
1. 统一化发展
- 多模态模型成为主流
- 单一模型处理多任务
- 减少模型切换成本
- 提升用户体验
2. 智能化升级
- 自然语言交互增强
- 上下文理解能力提升
- 个性化定制服务
- 自适应学习机制
技术发展方向
1. 短期目标(2025年)
- 模型性能持续优化
- 支持更多应用场景
- 社区生态完善
- 工具链集成
2. 长期愿景(2026-2027年)
- 实时交互能力
- 多模态融合增强
- 边缘设备部署
- 个性化AI助手
结语
OmniGen2的推出标志着AI图像生成技术进入了一个新的发展阶段。通过统一的多模态架构、强大的图像编辑能力和开源的生态建设,OmniGen2不仅解决了传统图像生成模型的痛点,更为未来的AI创作工具奠定了坚实基础。
随着技术的不断成熟和社区的持续贡献,我们有理由相信,OmniGen2将在创意设计、内容创作、教育培训等众多领域发挥重要作用,真正实现”一个模型,无限可能”的愿景。
对于开发者和研究者而言,OmniGen2提供了一个绝佳的平台来探索多模态AI的无限潜力。让我们共同期待这项技术在未来带来的更多惊喜和突破。
相关链接: