DeepSeek FlashMLA 项目调研报告
DeepSeek FlashMLA 项目调研报告
摘要
本报告对 DeepSeek 的 FlashMLA 项目进行了深入调研,包括项目的核心功能、关键技术、创新点、代码结构、依赖关系及组件交互。FlashMLA 是一个高效的多头线性注意力(Multi-head Linear Attention, MLA)解码内核,专为 NVIDIA Hopper 架构 GPU 优化,特别适用于变长序列服务场景。本报告通过系统架构图、数据流图、UML 类图、状态图和时序图等多种可视化方式,展示了 FlashMLA 的内部工作机制,并与 FlashAttention、CUTLASS 等同类工具进行了技术对比,分析了其在大型语言模型推理、在线服务部署、多模态模型等场景中的应用价值。
1. 项目概述
1.1 项目背景
随着大型语言模型(LLM)的规模和复杂度不断增加,注意力机制的计算效率成为影响模型推理性能的关键因素。传统的 Transformer 架构中的自注意力机制计算复杂度为 O(n²),在处理长序列时面临严重的性能瓶颈。线性注意力(Linear Attention)作为一种计算复杂度为 O(n) 的替代方案,在理论上具有显著优势,但在实际工程实现中仍面临诸多挑战。
DeepSeek 团队开发的 FlashMLA 项目旨在为线性注意力机制提供高效的 CUDA 实现,特别针对 NVIDIA 最新的 Hopper 架构进行了深度优化,以充分发挥其硬件特性,提升大型语言模型在推理阶段的性能。
1.2 核心功能
FlashMLA 提供以下核心功能:
- 高效的多头线性注意力计算:实现了计算复杂度为 O(n) 的线性注意力机制,显著提升长序列处理能力
- 分页 KV 缓存支持:支持块大小为 64 的分页 KV 缓存,优化内存使用和访问模式
- 变长序列处理:专门针对变长序列服务场景进行了优化
- 精度支持:支持 BF16 和 FP16 数据类型
- Hopper 架构优化:充分利用 NVIDIA Hopper 架构的硬件特性,如 TMA (Tensor Memory Accelerator)
1.3 关键技术
FlashMLA 项目采用了以下关键技术:
- 分片计算策略:通过 splitkv_mla 实现 K、V 矩阵的分片处理,减少内存占用
- 跷跷板调度算法:实现了高效的计算任务分配,平衡 GPU 资源利用
- 细粒度 TMA 拷贝:利用 Hopper 架构的 TMA 功能,优化内存访问模式
- GEMM 流水线:实现计算与内存访问的并行,提高吞吐量
- CUTLASS 库集成:利用 NVIDIA CUTLASS 库提供的高性能矩阵乘法原语
1.4 创新点
FlashMLA 项目的主要创新点包括:
- 针对 Hopper 架构的深度优化:充分利用 H100/H800 GPU 的硬件特性,实现接近理论峰值的性能
- 分页 KV 缓存设计:创新的缓存管理方案,提高内存利用效率
- 变长序列优化:专门针对实际应用中常见的变长序列场景进行了优化
- 高效的分片与合并算法:通过精心设计的分片计算和结果合并策略,平衡计算负载
- 内存带宽优化:在内存受限配置下可达到 3000 GB/s,接近 H800 SXM5 GPU 的理论带宽上限
2. 代码结构与依赖分析
2.1 项目整体代码结构
FlashMLA 项目的代码结构清晰,主要分为以下几个部分:
1 | FlashMLA/ |
2.2 主要组件间的依赖关系
FlashMLA 项目的组件依赖关系如下:
- Python API 层:依赖 C++ 接口层,提供用户友好的接口
- C++ 接口层:依赖 CUDA 内核层,负责参数验证和内核调用
- CUDA 内核层:依赖 CUTLASS 库,实现核心计算逻辑
- CUTLASS 库:提供高性能的矩阵乘法和内存操作原语
这种分层设计使得项目结构清晰,各层职责明确,便于维护和扩展。
2.3 组件交互方式
FlashMLA 的组件交互主要通过以下方式进行:
- Python 到 C++ 的交互:通过 PyTorch 的 C++ 扩展机制,Python API 调用 C++ 接口
- C++ 到 CUDA 的交互:C++ 接口负责参数验证和内存管理,然后调用 CUDA 内核
- CUDA 内核间的交互:splitkv_mla 内核完成计算后,mla_combine 内核负责合并结果
- CUDA 与 CUTLASS 的交互:CUDA 内核通过调用 CUTLASS 提供的模板函数实现高效计算
2.4 外部依赖库
FlashMLA 项目主要依赖以下外部库:
- PyTorch:提供张量操作和 CUDA 扩展支持
- CUTLASS:NVIDIA 的高性能 CUDA 模板库,提供矩阵乘法原语
- CUDA Toolkit:提供 CUDA 编译和运行环境
- CUB:CUDA 的通用构建块库,提供高效的并行算法
3. 系统架构与数据流
3.1 系统架构图
下图展示了 FlashMLA 的系统架构,包括从 Python API 到 CUDA 内核的各层组件及其关系:
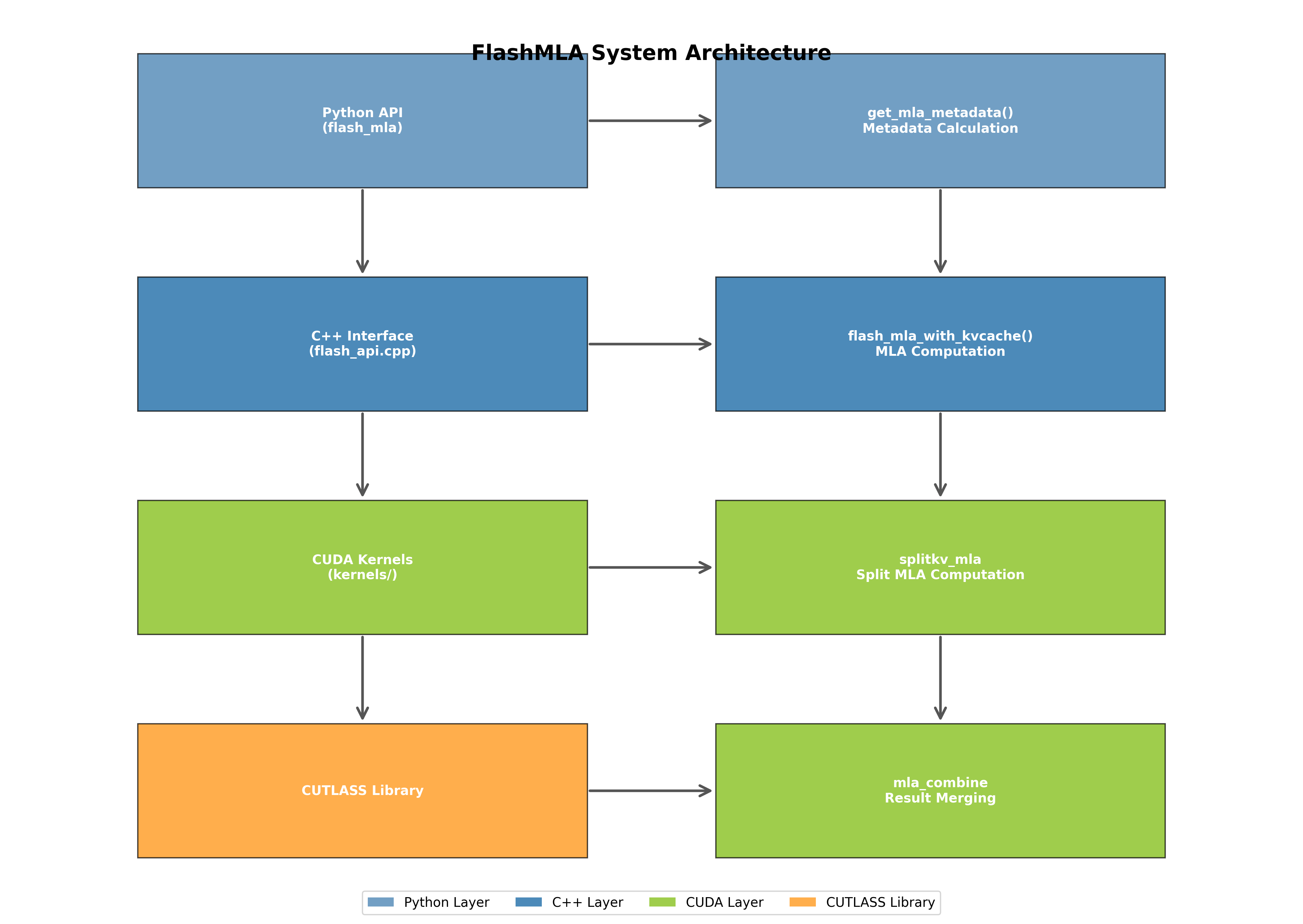
系统架构分为四个主要层次:
- Python 层:提供用户友好的 API 接口
- C++ 层:负责参数验证和内核调用
- CUDA 层:实现核心计算逻辑
- CUTLASS 库:提供底层计算原语
3.2 数据流图
下图展示了 FlashMLA 中数据的流动路径和处理步骤:
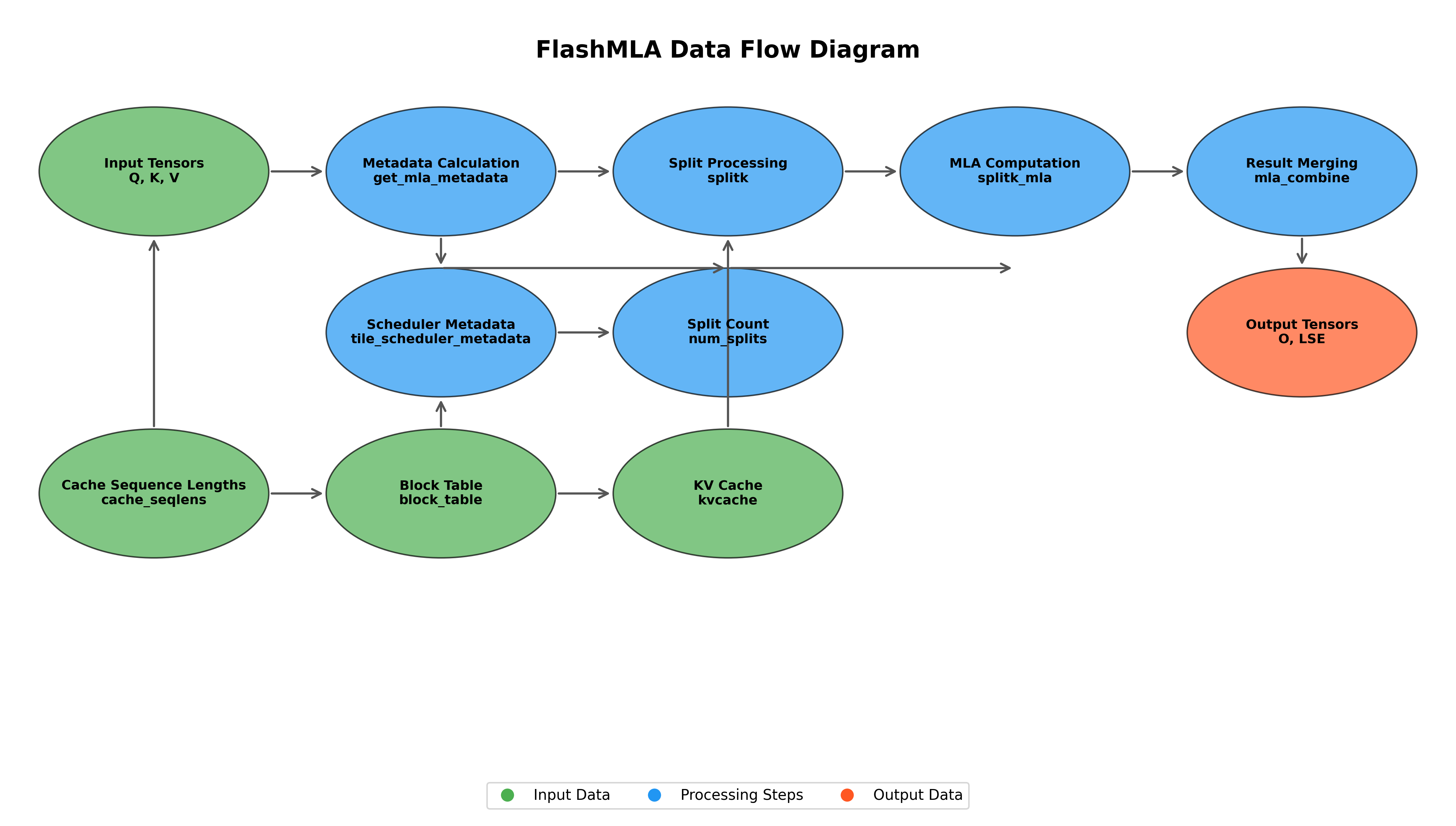
数据流程主要包括:
- 输入张量(Q、K、V)和 KV 缓存进入系统
- 元数据计算生成调度信息
- 分片处理将计算任务分配到多个计算单元
- MLA 计算执行核心算法
- 结果合并生成最终输出张量
3.3 UML 类图
下图展示了 FlashMLA 的主要类及其关系:
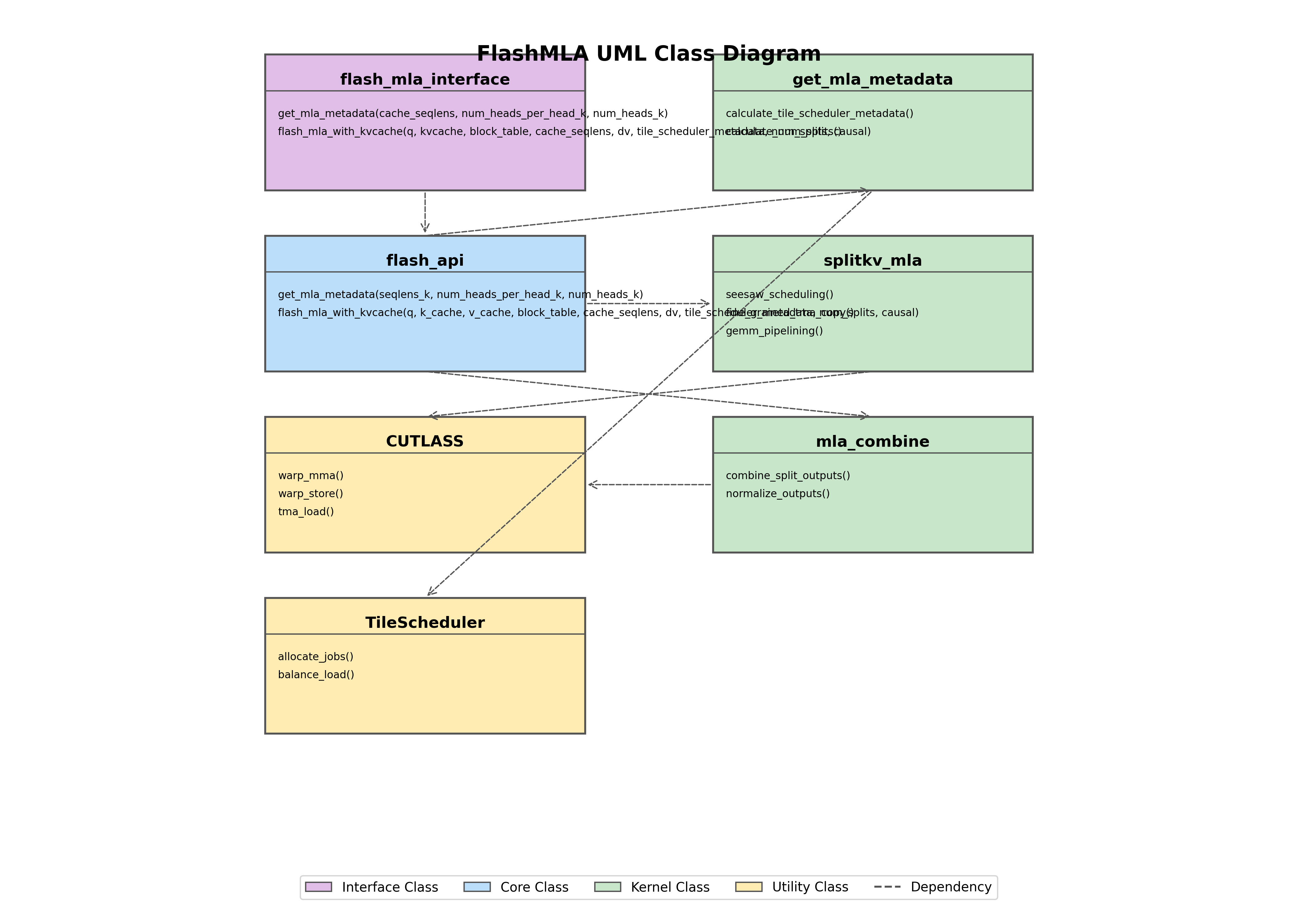
UML 类图展示了四种主要类型:
- 接口类:定义外部调用接口
- 核心类:实现主要业务逻辑
- 内核类:实现具体计算功能
- 工具类:提供辅助功能
3.4 状态图
下图展示了 FlashMLA 执行过程中的状态转换:
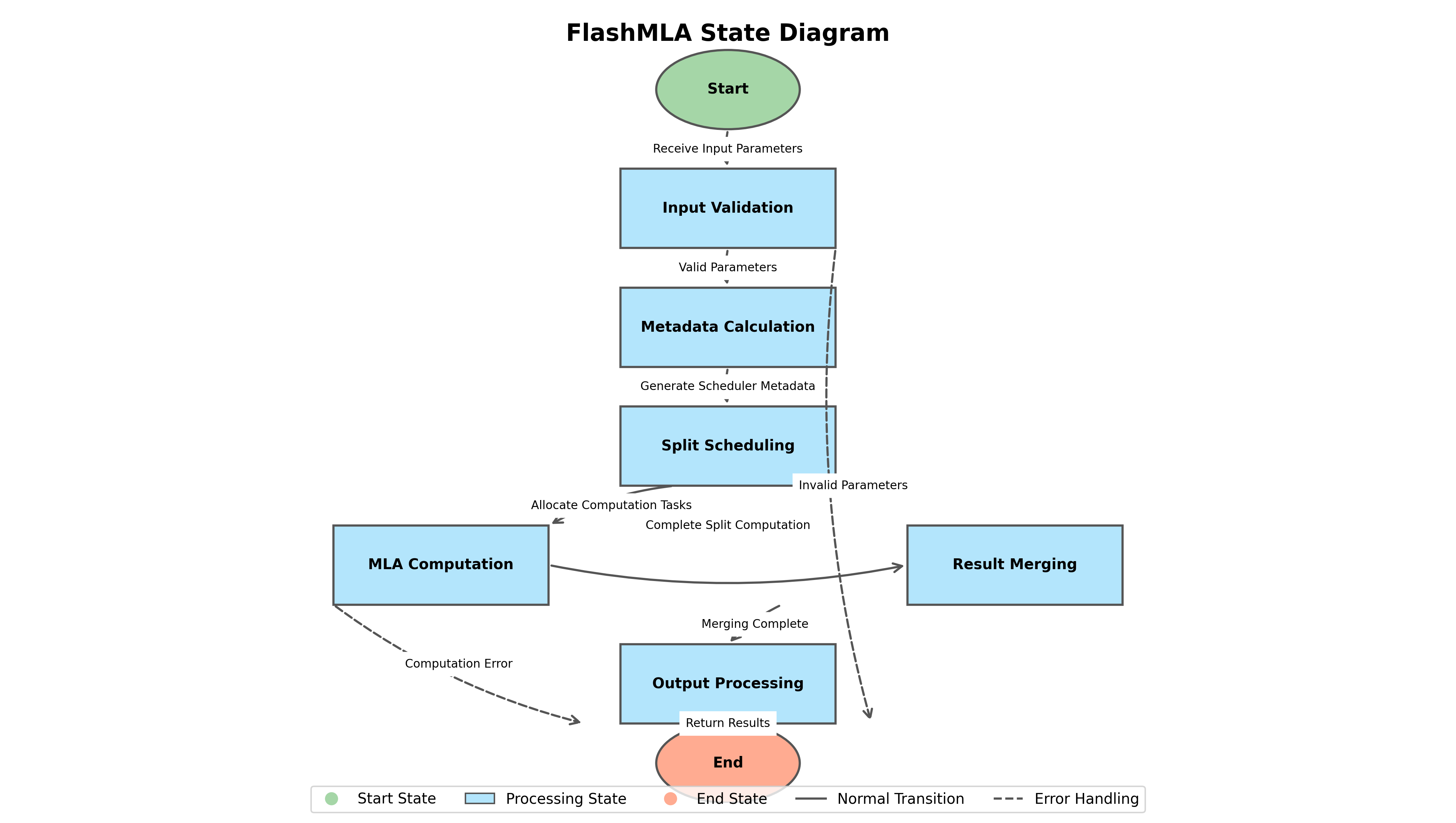
状态图展示了从输入验证到输出处理的完整流程,包括正常路径和错误处理路径。
3.5 时序图
下图展示了 FlashMLA 执行过程中各组件的交互时序:
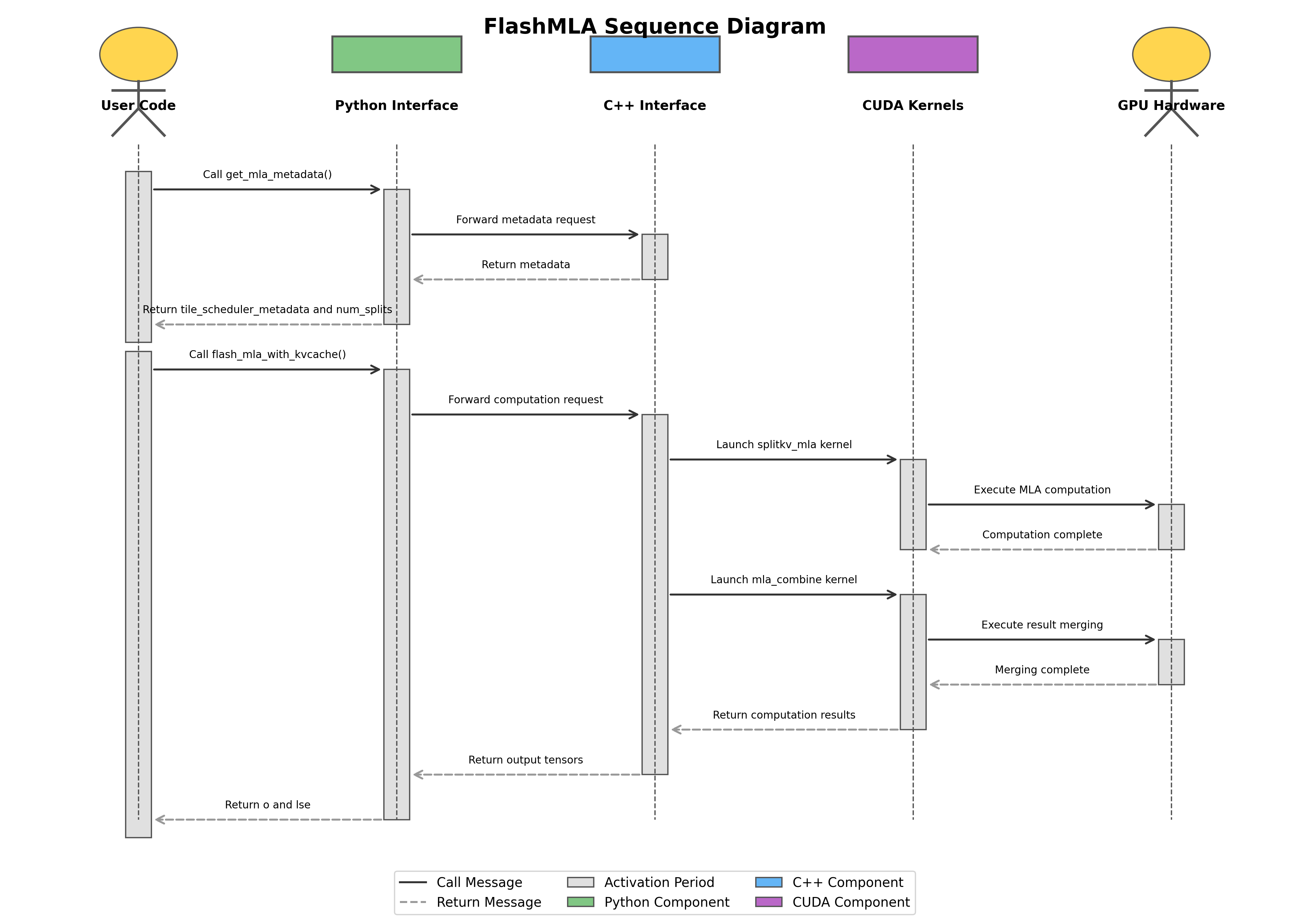
时序图详细展示了从用户代码调用到最终返回结果的完整交互过程,包括两个主要阶段:
- 元数据计算阶段
- MLA 计算与结果合并阶段
4. 核心算法与实现细节
4.1 多头线性注意力算法
FlashMLA 实现的多头线性注意力算法基于以下数学公式:
1 | Attention(Q, K, V) = D^(-1) * (Q * K^T) * V |
其中:
- Q 是查询矩阵
- K 是键矩阵
- V 是值矩阵
- D 是归一化因子
与传统的 softmax 注意力不同,线性注意力避免了 softmax 计算,将计算复杂度从 O(n²) 降低到 O(n),特别适合处理长序列。
4.2 分片计算策略
FlashMLA 采用了分片计算策略,主要包括以下步骤:
- 元数据计算:根据输入序列长度和头数计算调度元数据
- 分片划分:将计算任务划分为多个分片,每个分片处理部分 K、V 数据
- 并行计算:各分片并行执行 MLA 计算
- 结果合并:将各分片的计算结果合并,生成最终输出
这种策略有效平衡了计算负载,提高了 GPU 资源利用率。
4.3 跷跷板调度算法
FlashMLA 实现了创新的跷跷板调度算法(Seesaw Scheduling),主要特点包括:
- 动态负载均衡:根据序列长度和头数动态调整计算任务分配
- 资源感知:考虑 GPU 的 SM(流多处理器)数量和内存带宽,优化任务分配
- 优先级调度:为关键路径上的计算任务分配更高优先级
这种调度算法显著提高了 GPU 利用率,减少了计算资源的空闲时间。
4.4 细粒度 TMA 拷贝
FlashMLA 充分利用 Hopper 架构的 TMA(Tensor Memory Accelerator)功能,实现了细粒度的内存拷贝:
- 异步拷贝:利用 TMA 实现计算与内存拷贝的重叠
- 张量感知拷贝:TMA 理解张量布局,优化内存访问模式
- 预取机制:提前加载下一批数据,减少内存延迟影响
这些优化使得 FlashMLA 能够高效利用内存带宽,在内存受限场景下接近理论带宽上限。
4.5 GEMM 流水线
FlashMLA 实现了高效的 GEMM(通用矩阵乘法)流水线:
- 多级流水线:将 GEMM 操作分解为多个阶段,实现并行执行
- 双缓冲技术:使用双缓冲区减少内存访问延迟
- 计算与访存重叠:当前数据计算与下一批数据加载并行执行
这种流水线设计显著提高了计算吞吐量,使 FlashMLA 在计算受限场景下能够达到 660 TFLOPS。
5. 性能与技术对比
5.1 与类似工具的对比
下图展示了 FlashMLA 与 FlashAttention、CUTLASS MLP 等类似工具在多个维度的对比:
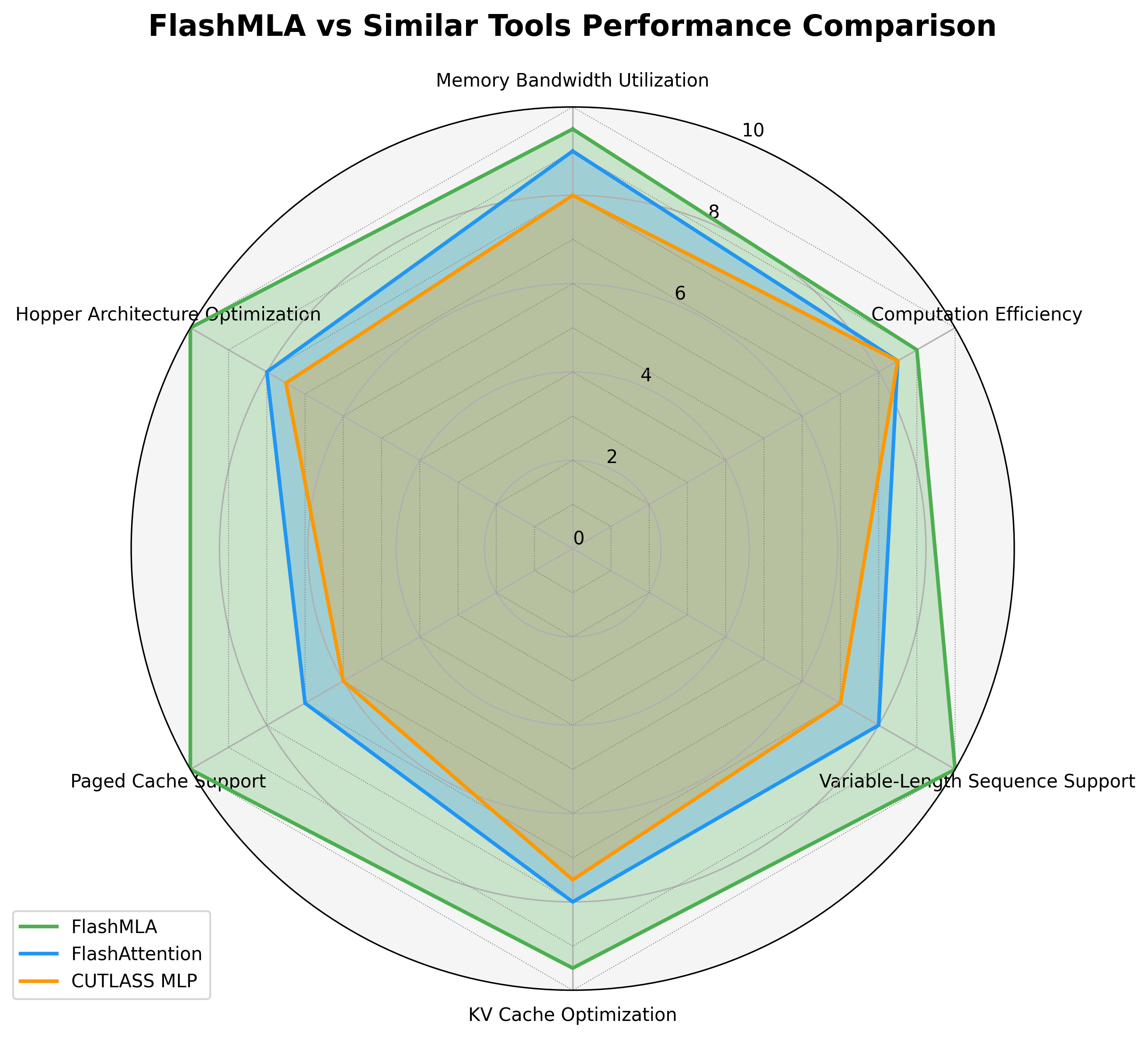
从雷达图可以看出,FlashMLA 在以下方面具有明显优势:
- 变长序列支持
- KV 缓存优化
- 分页缓存支持
- Hopper 架构优化
5.2 性能对比
下图展示了 FlashMLA 与其他工具在 H800 SXM5 GPU 上的性能对比:
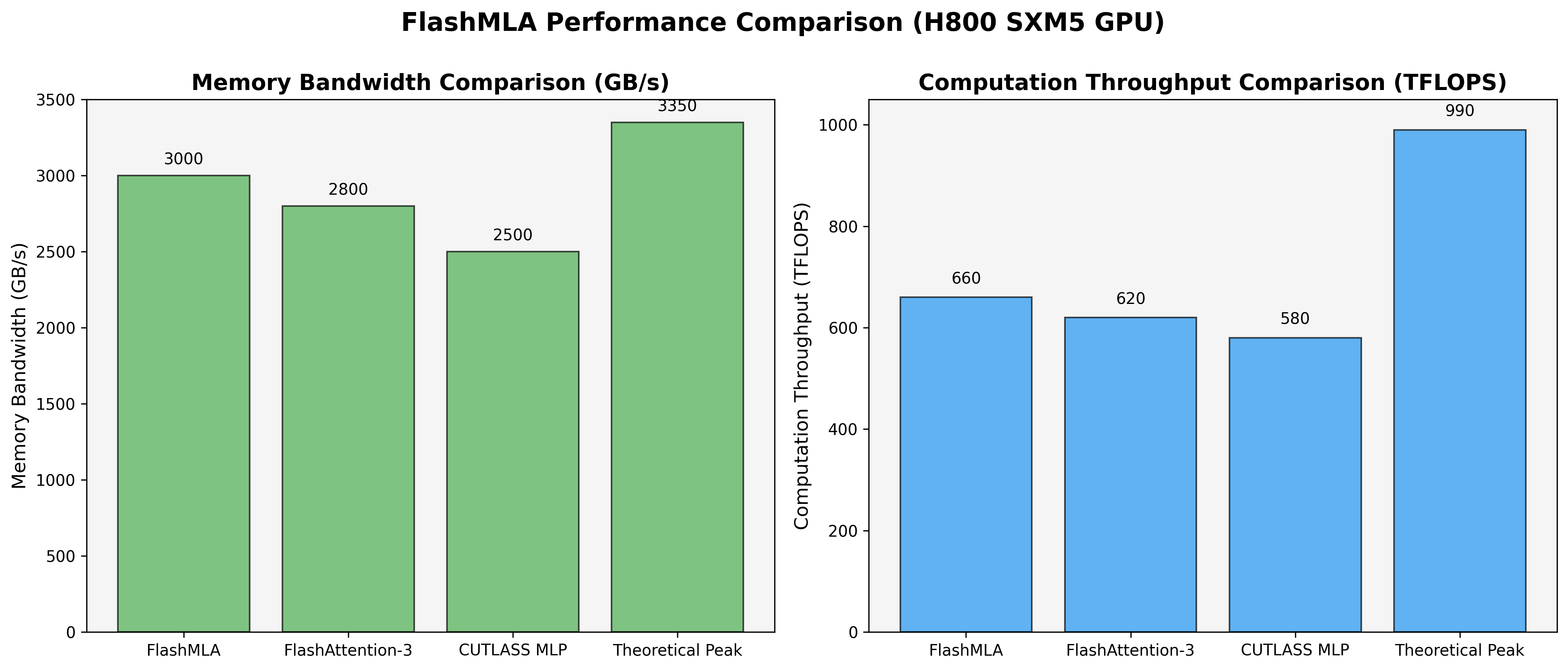
性能对比显示:
- 内存带宽:FlashMLA 达到 3000 GB/s,比 FlashAttention-3 高 7.1%,比 CUTLASS MLP 高 20%
- 计算吞吐量:FlashMLA 达到 660 TFLOPS,比 FlashAttention-3 高 6.5%,比 CUTLASS MLP 高 13.8%
5.3 技术创新对比
与其他类似工具相比,FlashMLA 的主要技术创新包括:
| 特性 | FlashMLA | FlashAttention-3 | CUTLASS MLP |
|---|---|---|---|
| 注意力类型 | 线性注意力 | Softmax 注意力 | MLP 计算 |
| 计算复杂度 | O(n) | O(n²) | O(n) |
| 分页 KV 缓存 | 支持 | 部分支持 | 不支持 |
| Hopper 架构优化 | 全面优化 | 部分优化 | 部分优化 |
| 变长序列支持 | 专门优化 | 基本支持 | 有限支持 |
| TMA 利用 | 细粒度优化 | 基本利用 | 基本利用 |
| 调度算法 | 跷跷板调度 | 块级调度 | 静态调度 |
6. 应用场景分析
6.1 主要应用场景
FlashMLA 适用于多种应用场景,如下图所示:
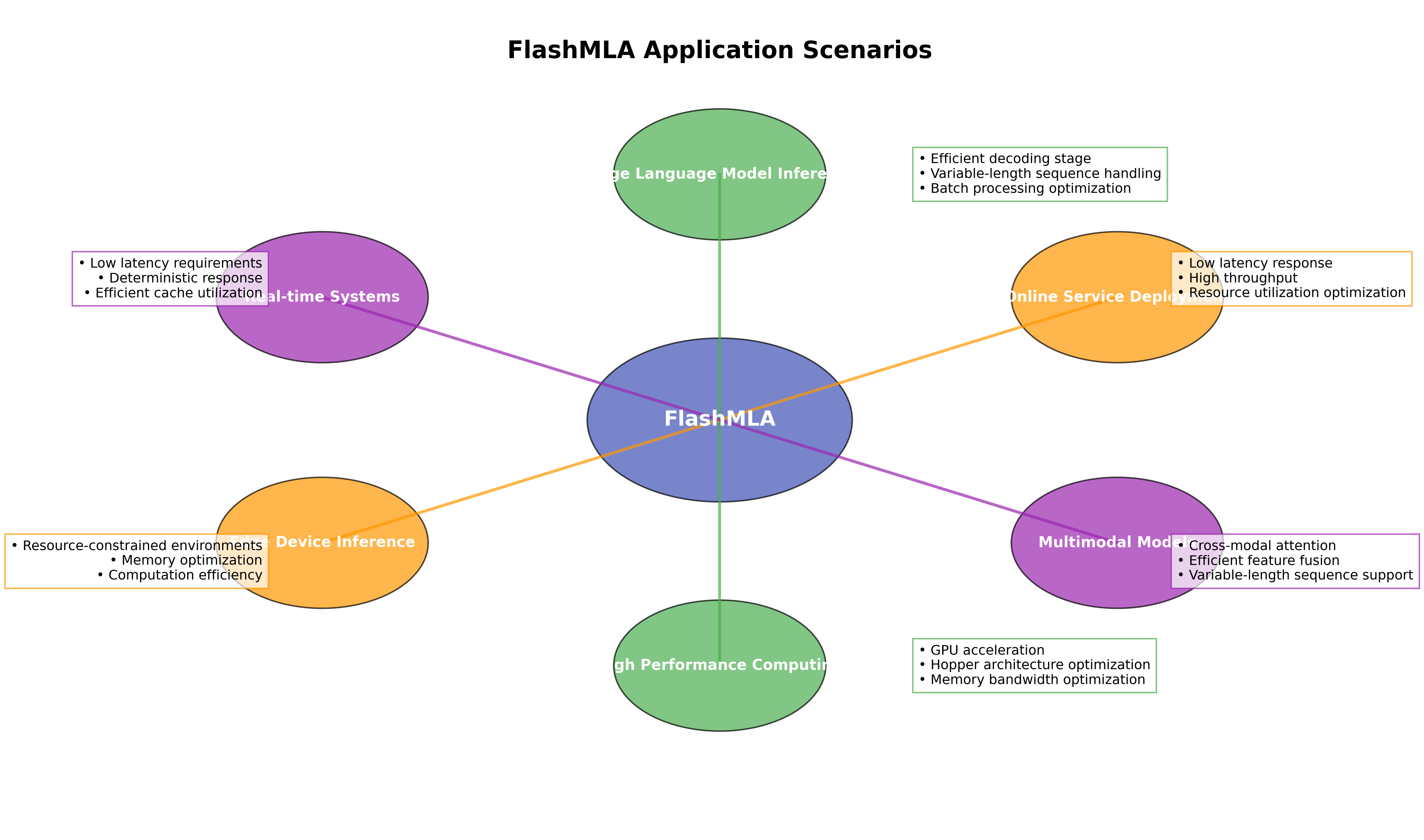
主要应用场景包括:
大型语言模型推理
- 高效解码阶段处理
- 变长序列处理
- 批处理优化
在线服务部署
- 低延迟响应
- 高吞吐量
- 资源利用率优化
多模态模型
- 跨模态注意力计算
- 高效特征融合
- 变长序列支持
高性能计算
- GPU 加速
- Hopper 架构优化
- 内存带宽优化
边缘设备推理
- 资源受限环境
- 内存优化
- 计算效率提升
实时系统
- 低延迟要求
- 确定性响应
- 高效缓存利用
6.2 大型语言模型推理场景
在大型语言模型推理场景中,FlashMLA 具有以下优势:
- 解码效率提升:线性注意力机制使得解码阶段的计算复杂度从 O(n²) 降低到 O(n),显著提高长文本生成效率
- 内存占用减少:分页 KV 缓存设计减少了内存占用,支持更长的上下文窗口
- 吞吐量提升:优化的计算流水线提高了模型推理吞吐量,支持更多并发请求
6.3 在线服务部署场景
在在线服务部署场景中,FlashMLA 的优势包括:
- 低延迟:高效的计算和内存访问模式减少了请求处理延迟
- 资源效率:优化的 GPU 资源利用提高了服务器利用率,降低了部署成本
- 可扩展性:良好的变长序列支持使系统能够处理不同长度的用户输入
6.4 多模态模型场景
在多模态模型场景中,FlashMLA 的优势包括:
- 跨模态融合:高效的注意力计算支持不同模态数据(文本、图像、音频等)的特征融合
- 异构序列处理:变长序列支持适应不同模态数据的长度差异
- 计算效率:线性复杂度算法减轻了多模态模型中的计算瓶颈
7. 总结与展望
7.1 技术总结
FlashMLA 项目通过一系列创新技术,为线性注意力机制提供了高效的 CUDA 实现:
- 算法创新:实现了 O(n) 复杂度的线性注意力,适用于长序列处理
- 架构优化:针对 Hopper 架构进行了深度优化,充分利用 TMA 等硬件特性
- 内存优化:分页 KV 缓存和细粒度 TMA 拷贝显著提高了内存利用效率
- 调度优化:跷跷板调度算法实现了高效的计算任务分配
- 工程实现:清晰的分层设计和模块化结构使代码易于维护和扩展
这些技术使 FlashMLA 在内存带宽和计算吞吐量方面达到了接近理论峰值的性能,为大型语言模型的推理提供了强大支持。
7.2 局限性分析
尽管 FlashMLA 具有显著优势,但仍存在一些局限性:
- 硬件依赖:深度优化针对 Hopper 架构,在其他架构上性能可能受限
- 线性注意力局限:线性注意力虽然计算效率高,但在某些任务上的表现可能不如传统 softmax 注意力
- 模型适配:现有模型多基于传统注意力机制训练,使用线性注意力可能需要模型适配或微调
- 实现复杂性:高度优化的 CUDA 代码增加了维护和扩展的复杂性
7.3 未来展望
FlashMLA 项目的未来发展方向可能包括:
- 多架构支持:扩展对 NVIDIA 其他架构(如 Ampere、Ada Lovelace)的优化支持
- 混合精度优化:进一步优化混合精度计算,平衡精度和性能
- 更多注意力变体:支持更多线性注意力变体,如 Performer、Linear Transformer 等
- 分布式计算:支持多 GPU 和多节点分布式计算,处理更大规模模型
- 与训练框架集成:深度集成到主流训练框架,支持端到端的训练和推理优化
参考资料
- DeepSeek FlashMLA GitHub 仓库:https://github.com/deepseek-ai/FlashMLA
- NVIDIA CUTLASS 库:https://github.com/NVIDIA/cutlass
- Hopper 架构白皮书:https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-hopper-architecture-whitepaper.pdf
- 线性注意力相关论文:
- “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”
- “Efficient Attention: Attention with Linear Complexities”
- “Performer: Rethinking Attention with Performers”